Message Queues and Brokers Help With Temporal Decoupling
One of the more common reactions I hear when engineers first encounter a message broker in a service-to-service communication context is that it feels like overengineering. Why introduce Kafka or RabbitMQ when a plain HTTP call does the same job with less infrastructure? It’s a fair question on the surface, and the people asking it aren’t wrong that a broker adds operational complexity. What they’re missing is that the complexity isn’t incidental — it’s the cost of a structural property that HTTP simply cannot give you: temporal decoupling.
When services communicate over HTTP or gRPC, they are temporally coupled. That phrase is worth unpacking because it carries more weight than it might first appear. Temporal coupling means that both sides of a call must be available at the same moment for work to succeed. The caller needs to send, and the receiver needs to receive, right now. If the downstream service is down — restarting, overloaded, mid-deploy, or in the middle of a slow garbage collection pause — the call fails, and the caller has to decide what to do about it.
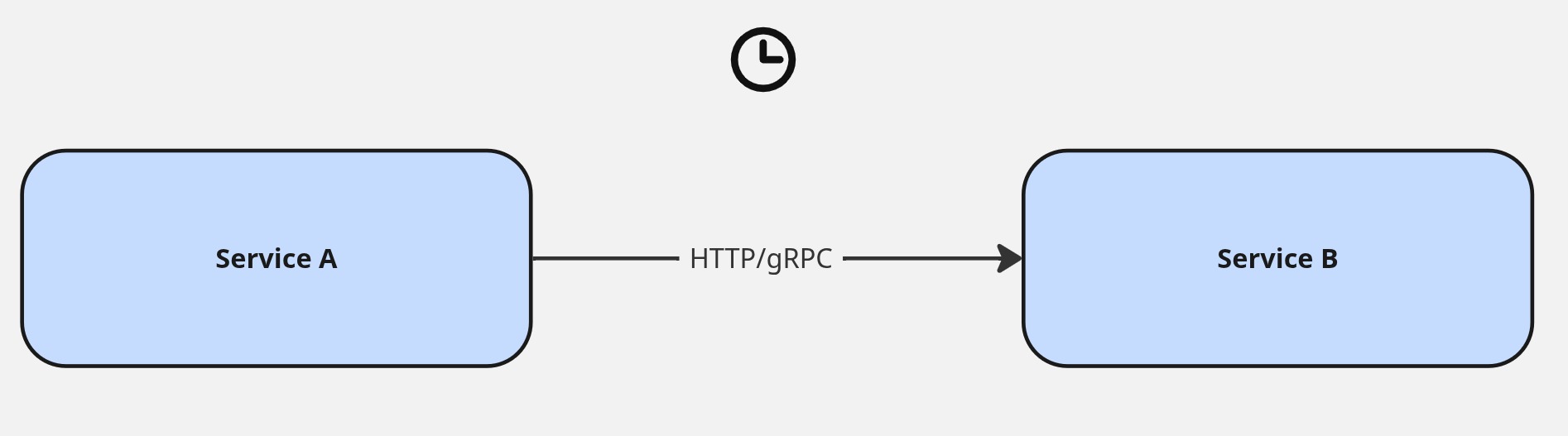
That decision is where the real complexity lives. The simplest response to a failed HTTP/gRPC call is a retry: wait a moment and try again. Add exponential backoff and a jitter, and you have a reasonably robust mechanism for handling transient failures. But this only works when the caller can afford to wait and when the operation is idempotent. The moment you’re dealing with something that has side effects — a payment, an inventory reservation, an order placement — naive retries introduce the risk of double-processing. So now you need idempotency keys, deduplication logic, and a way to distinguish “the call failed” from “the call succeeded but the response never arrived.”
And it keeps growing from there. If you need to survive failures that last longer than a few seconds — a downstream service that’s down for minutes or hours — you can’t just loop on retries. You need the caller to store enough state to pick up where it left off: the current transaction state, which step failed, and the business rules for how to resume. You’ve effectively implemented a workflow engine inside a service that wasn’t designed to be one. What started as a simple service call has turned your upstream service into a stateful coordinator that knows too much about what the downstream service is doing and how it fails. That’s tight coupling masquerading as resilience.
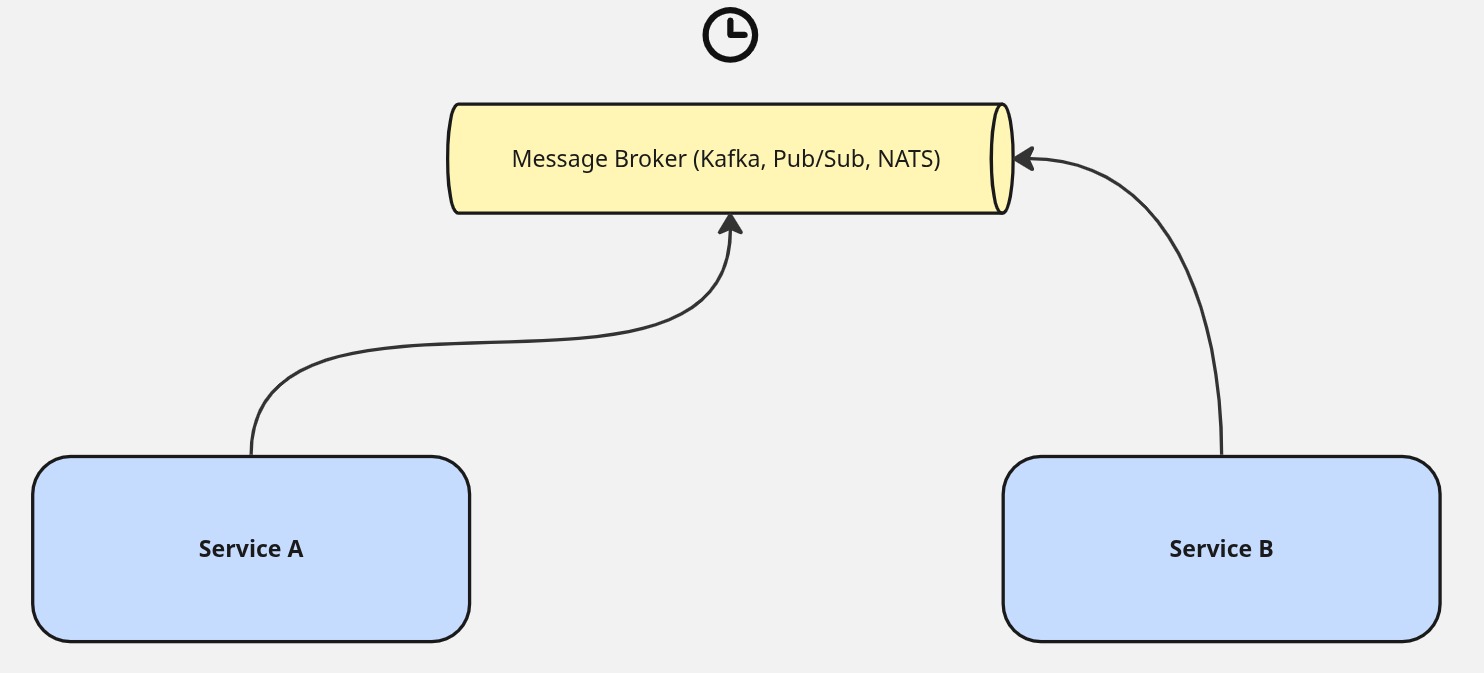
A message broker changes the contract entirely. When a service publishes a message to a broker, its job is done. It doesn’t wait for an acknowledgment from the consuming service. It doesn’t need to know whether the consumer is up. It doesn’t retry, doesn’t store state on behalf of the downstream, and doesn’t implement any logic for what happens if processing fails on the other side. The publishing service and the consuming service are no longer required to be available at the same time — hence temporal decoupling. The broker holds the message until the consumer is ready to process it, and the consumer processes at its own pace, on its own schedule, independent of whatever the producer is doing.
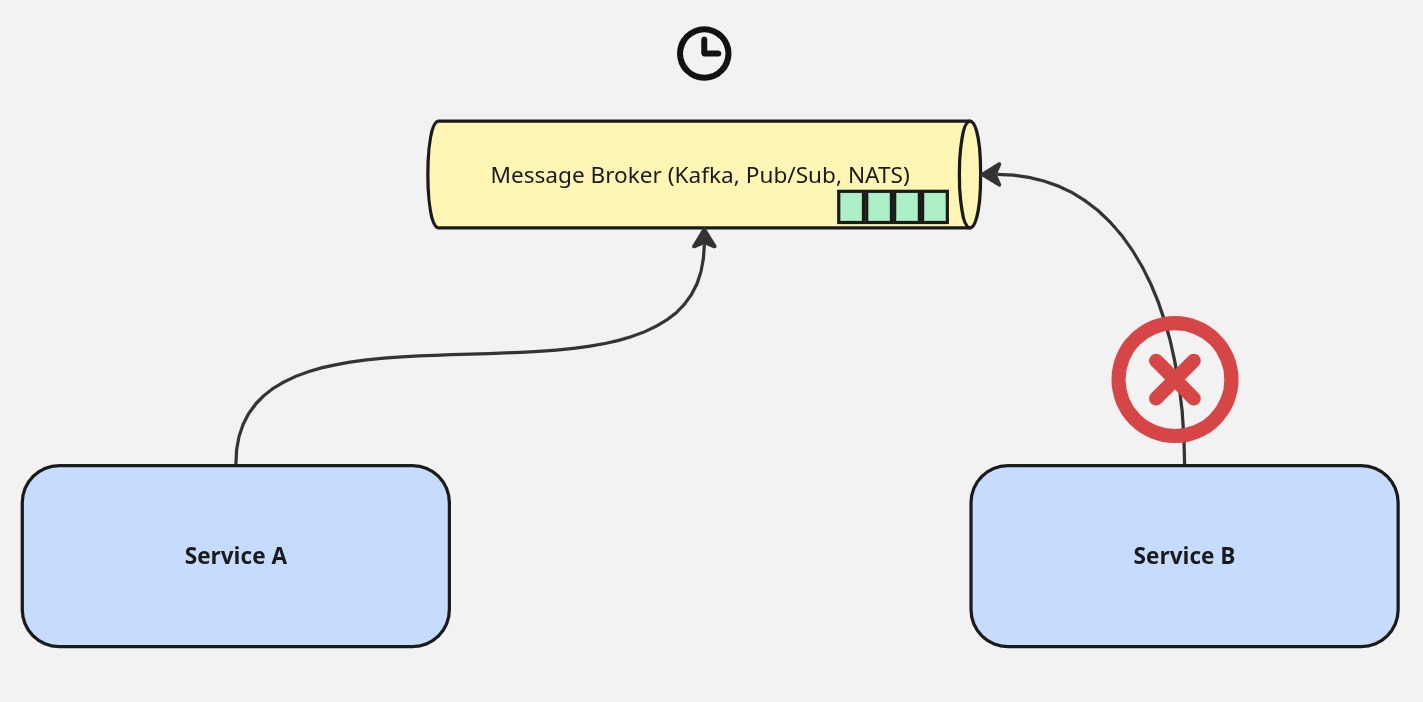
This shifts the failure model in a meaningful way. If a consuming service goes down, messages accumulate in the broker. When the service comes back up, it resumes from where it left off. No messages are lost, no callers are blocked, and no upstream service needs to know anything about the outage that happened downstream. Each service is responsible for its own reliability, its own processing rate, and its own error handling. The producer’s concern ends at publishing; the consumer’s concern begins at reading. The broker is the handoff point, and neither side needs to be aware of the other’s internal state.
This is the property that engineers miss when they look at a broker and see only infrastructure overhead. The overhead is real, but so is what it buys. Temporal decoupling isn’t a nice-to-have abstraction — it’s the structural difference between a distributed system where services prop each other up and one where they can operate, fail, and recover independently. A system built on synchronous HTTP or gRPC calls between services can be made more resilient, but only by pushing the coordination burden onto the callers. A system built around a broker distributes that responsibility differently: the broker handles durability, and each service handles its own processing. That’s not more convoluted. That’s a cleaner separation of concerns.